- Metadatos admitidos
- Añadir un nuevo dataset
- Subir archivos
- Manejo de archivos
- Editar archivos
- Reemplazar archivos
- Condiciones
- Roles y permisos
- Procedencia de los datos
- Imágenes en miniatura + Widgets
- Publicar dataset
- Enviar para revisión
- URL privada para revisar datasets sin publicar
- Versiones de dataset
- Métricas de datasets y Make Data Count
- Almacenamiento y computación en la nube
- Eliminar acceso a un dataset
En Dataverse, un dataset funciona como un contenedor para sus datos, documentación, código y los metadatos que describen ese dataset.
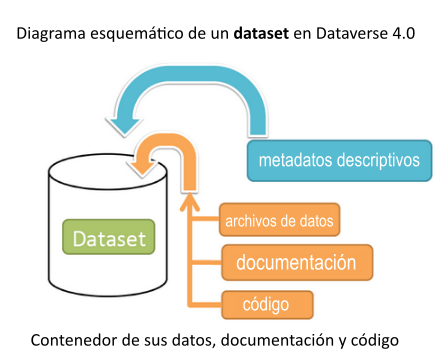
Metadatos admitidos
Un dataset contiene tres niveles de metadatos:
- Metadatos de cita: cualquier metadato necesario para generar una cita de datos y otros metadatos generales y aplicables a cualquier dataset.
- Metadatos específicos del área disciplinar: actualmente con soporte específico para datasets de Ciencias Sociales, Ciencias de la Vida, Geoespaciales y de Astronomía y Astrofísica.
- Metadatos a nivel de archivo: varían según el tipo de archivo de datos. Para obtener más detalles, consulte el apartado “Manejo de archivos” más abajo.
Para obtener más detalles sobre los metadatos de cita y específicos del área disciplinar que se admiten, consulte el Apéndice de esta Guía de usuario.
Formatos de exportación de metadatos admitidos
Ya publicado un dataset, sus metadatos pueden exportarse en una variedad de estándares y formatos de metadatos, para volverlos visibles y utilizables en otros sistemas, por ejemplo, otros repositorios de datos. En la pestaña de metadatos de la página del dataset, se encuentran disponibles las siguientes opciones de exportación:
- Dublin Core
- DDI (Data Documentation Initiave Codebook 2.5)
- HTML DDI Codebook (una versión HTML más legible de la exportación de metadatos DDI Codebook 2.5)
- DataCite 4
- JSON (formato nativo de Dataverse)
- OAI_ORE
- OpenAIRE
- Schema.org JSON-LD
Cada una de estas exportaciones contendrá los metadatos de la versión más reciente del dataset.
Añadir un nuevo dataset
- Navegue hasta el dataverse donde desea añadir un nuevo dataset.
- Haga clic en el botón “Añadir Datos” y seleccione “Nuevo dataset” del menú desplegable.
- Para comenzar rápidamente, complete como mínimo los campos obligatorios, indicados con un asterisco (p. ej., título del dataset, autor, descripción, e-mail de contacto y materia). De esta forma obtendrá una cita de datos con un DOI.
- Desplácese hacia abajo hasta la sección Archivos y haga clic en “Seleccione los archivos que quiera añadir” para agregar todos los archivos relevantes a su dataset. También, puede cargar sus archivos directamente desde Dropbox. Sugerencia: puede arrastrar y soltar o seleccionar varios archivos a la vez directamente desde su escritorio en el widget de carga. Sus archivos aparecerán debajo del botón “Seleccione los archivos que quiera añadir” donde podrá agregar una descripción y etiquetas para cada archivo desde el botón “Editar”. Además, se añadirá una suma de comprobación MD5 para cada archivo. Si carga un archivo de datos tabulares, se añadirá una Huella Digital Numérica Universal (UNF).
- Haga clic en el botón “Guardar dataset” cuando haya finalizado y habrá creado su dataset sin publicar.
Nota: una vez que haya creado su dataset, podrá añadir metadatos adicionales. Para esto vaya a la página del dataset, en el botón “Editar” > “Metadatos”.
Actualmente nuestros cuadros de texto para campos de metadatos (p. ej. Descripción) solo admiten las siguientes etiquetas HTML: <a>, <b>, <blockquote>, <br>, <code>, <del>, <dd>, <dl>, <dt>, <em>, <hr>, <h1>-<h3>, <i>, <img>, <kbd>, <li>, <ol>, <p>, <pre>, <s>, <sup>, <sub>, <strong>, <strike>, <ul>.
Subir archivos
El software Dataverse ofrece varios métodos para cargar archivos en un dataset. El administrador de una instalación de Dataverse puede configurar estos métodos de carga, por lo que es posible que algunas de estas opciones no se visualicen en el sitio de Dataverse que está utilizando.
Si visualiza varias opciones de carga disponibles, puede elegir la que prefiera para su dataset. Cada dataset podrá usar solo un método de carga. Una vez que se produzca la carga de un archivo mediante uno de los métodos de carga disponibles, este método queda seleccionado de forma permanente para ese dataset. Si necesita cambiar el método de carga de un dataset que ya contiene archivos, comuníquese con el Soporte técnico, mediante el enlace “Soporte” en el extremo superior de la página.
Puede cargar archivos en un dataset mientras lo está creando. También puede cargar archivos después de crear el dataset haciendo clic en el botón “Editar” en la esquina superior derecha de la página del dataset, seleccionando la opción “Archivo (subir)” de la lista desplegable, o haciendo clic en el botón “Subir archivos” en el extremo superior de la pestaña Archivos. Cualquiera de las dos opciones, lo dirigirá a la página Subir archivos de ese dataset.
En Dataverse, ciertos tipos de archivos son compatibles con funciones adicionales, que incluyen: descarga en diferentes formatos, conservación de metadatos a nivel de archivo, cita de datos a nivel de archivo con UNF y exploración a través de visualización y análisis de datos. Para más información, consulte la sección Manejo de archivos de esta Guía.
La subida de archivos desde HTTP es una herramienta común de carga de archivos basada en un navegador web con la que tal vez esté familiarizado, ya que otras aplicaciones web la utilizan. Puede subir los archivos a través de un HTTP seleccionándolo desde su navegador o arrastrándo y soltándolo en el widget de carga.
Una vez que haya subido los archivos, podrá editar los metadatos, restringir el acceso,[1] y/o añadir etiquetas. Haga clic en “Guardar cambios” para completar la carga. Si subió un archivo por error, puede eliminarlo antes de guardarlo haciendo clic en la casilla de verificación para seleccionar el archivo y luego haciendo clic en el botón “Eliminar”, que se ubica sobre la tabla de archivos.
El tamaño máximo para carga de archivos varía según la instalación de Dataverse. Estará indicado en el texto que aparece sobre el widget de carga HTTP. Si necesita subir un archivo de gran tamaño o una gran cantidad de archivos, considere usar la opción de carga rsync + SSH, siempre que su instalación de Dataverse ofrezca esta alternativa.
[1] Esta característica no se encuentra habilitada en todas las instalaciones de Dataverse.
Algunas instalaciones de Dataverse admiten la carga directa de archivos desde Dropbox. Para esto, haga clic en el botón “Subir desde Dropbox”. En la ventana emergente, inicie sesión en Dropbox y seleccione los archivos que desea transferir.
Subir archivos por rsync + SSH
Rsync se utiliza generalmente para sincronizar archivos y directorios entre dos sistemas diferentes usando SSH, en lugar de HTTP, para conectarse. Algunas instalaciones de Dataverse permiten cargas mediante rsync, para facilitar la transferencia de archivos de gran tamaño de forma confiable y segura.
Secuencia de comando para carga de archivos
La instalación de Dataverse habilitada para rsync cuenta con un proceso de carga de archivos que difiere del tradicional basado en navegadores web al que estamos acostumbrados. Para transferir sus datos al almacenamiento en Dataverse, deberá seguir los siguientes pasos:
- Cree su dataset. En las instalaciones de Dataverse habilitadas para rsync, no podrá cargar los archivos hasta que finalice el proceso de creación del dataset. Después de hacer clic en “Guardar dataset” en la página de creación de dataset, será dirigido a la página de su dataset.
- En la página del dataset, haga clic en el botón “+ Subir archivos”. Se abrirá un cuadro de instrucciones y un enlace al script de carga del archivo.
- Asegúrese de que sus archivos estén listos para la carga. Necesitará contar con un solo directorio al que pueda apuntar el script de carga. Se cargarán todos los archivos de este directorio y de cualquier subdirectorio. La estructura del directorio se conservará y se reproducirá cuando su dataset sea descargado de Dataverse. Tenga en cuenta que sus datos se cargan en forma de paquete de datos, y que cada dataset solo podrá contener uno de esos paquetes. Asegúrese de que todos los archivos que desea subir estén incluidos en el directorio antes de la carga.
- Descargue el script de carga del archivo rsync haciendo clic en el botón “Download Script” (Descargar script) del cuadro de instrucciones “Subir archivos”. Puede guardar la secuencia de comando donde lo desee; asegúrese de poder encontrarla luego. La descarga del script de carga pondrá un bloqueo temporal en su dataset, con el fin de prepararlo para la carga. Mientras su dataset esté bloqueado, no podrá eliminarlo, publicarlo o editar los metadatos. Una vez que termine de cargar sus archivos y Dataverse los procese, su dataset se desbloqueará automáticamente y estas funciones volverán a habilitarse. Si descarga el script (bloqueando su dataset) y luego cambia de opinión y decide no subir los archivos, deberá comunicarse con el Soporte técnico para desbloquear su dataset.
- Para comenzar el proceso de carga, ejecute el script que descargó. Salga de su navegador y abra una ventana de terminal (también conocida como línea de comando) en su computadora. Utilice la terminal para navegar al directorio donde guardó el script de carga y ejecute el comando que se proporciona en el cuadro de instrucciones “Subir archivos”. Esto iniciará el script de carga. Tenga en cuenta que el script caducará 7 días después de haberla descargado. Si esto ocurre y aún necesita utilizarla, simplemente descargue la secuencia nuevamente.
Nota: a diferencia de otros sistemas operativos, Windows no incluye rsync compatible de forma predeterminada. No hemos optimizado esta función para los usuarios de Windows, pero puede funcionar instalando las utilidades de Unix adecuadas. (Si usted ha encontrado una manera de ejecutar esta función en Windows, puede contribuir a nuestro proyecto. Consulte nuestro documento Contributing to Dataverse en GitHub.
- Siga las instrucciones proporcionadas por la secuencia de comando que se ejecuta en su terminal. Le indicará que ingrese la ruta completa del directorio donde se encuentran los archivos para su dataset, y luego comenzará el proceso de carga. Si necesita cancelar la carga luego de haberla iniciado, puede hacerlo cancelando la secuencia de comando que se ejecuta en la terminal. Si su carga se interrumpe, puede reanudarla luego desde el mismo punto.
- Una vez que finalice el script de carga, Dataverse comenzará a procesar la carga de datos y ejecutará una suma de comprobación. Esto puede llevar cierto tiempo dependiendo del tamaño de los archivos que ha subido. Durante el procesamiento, verá una barra azul en la parte inferior de la página del dataset con la leyenda “Upload in progress…” (Subida en progreso).
- Una vez que finalice el procesamiento, aparecerá una notificación. Ya podrá publicar su dataset y sus datos estarán disponibles para descarga en la página del dataset.
Nota: un dataset puede contener solo un paquete de datos. Si necesita reemplazar el paquete de datos de su dataset, comuníquese con el Soporte técnico.
La herramienta DVUploader de código abierto es una aplicación Java de línea de comandos independiente que utiliza la API (interfaz de programación de aplicaciones) de Dataverse para cargar archivos en un dataset específico. Dado que los usuarios pueden instalarla y no requiere configuración del lado del servidor, se puede utilizar con cualquier instalación de Dataverse. Está pensada como una alternativa a la carga de archivos a través de la interfaz web de Dataverse en situaciones en las que dicha interfaz resulte inconveniente debido al volumen de archivos o a la ubicaciones de estos (cuando están distribuidos en varios directorios, mezclados con archivos que ya han sido cargados o tipos de archivo que deberían excluirse), o ante la necesidad de automatizar las cargas. Dado que DVUploader utiliza la API de Dataverse, las transferencias tienen las mismas limitaciones en cuanto a tamaño y rendimiento que las cargas HTTP a través de la interfaz web de Dataverse. DVUploader registra su actividad y puede cancelar y reiniciar la carga. Si se detiene y se reanuda un proceso, DVUploader continuará donde había quedado.
DVUploader es un software de código abierto y está disponible como fuente, como .jar de Java, y con la documentación correspondiente en el repositorio del proyecto en GitHub. DVUploader requiere Java 1.8+. Los usuarios que no poseen java deben instalarlo y luego descargar el archivo DVUploader-v1.0.0.jar. Los usuarios deberán conocer la URL del servidor de Dataverse, el DOI de su dataset y haber generado un token del API de Dataverse (opción que se encuentra en el menú desplegable del perfil del usuario).
Su uso básico consiste en ejecutar el comando:
java -jar DVUploader-v1.0.0.jar -server=<Dataverse server URL> -did=<Dataset DOI> -key=<User's API Key> <file or directory list>
Existen argumentos de línea de comando adicionales disponibles para hacer que DVUploader: enumere lo que hará sin iniciar la carga, limite el número de archivos de carga, ejecute procesos recursivos a través de subdirectorios, verifique la integridad, excluya archivos con extensiones o patrones de nombre específicos y/o espere más de 60 segundos antes de eliminar cualquier bloqueo de ingesta de Dataverse (por ej.: mientras se procesa un archivo cargado anteriormente, como se explica en la sección Manejo de archivos a continuación).
DVUploader es una herramienta desarrollada por la comunidad y con el apoyo de la Biblioteca Digital de Texas. Más información y soporte para DVUploader disponible en el repositorio de GitHub del proyecto.
Manejo de archivos
En Dataverse, ciertos tipos de archivos son compatibles con funciones adicionales, que incluyen: descarga en diferentes formatos, conservación de metadatos a nivel de archivo, cita de datos a nivel de archivo con UNF y exploración mediante visualización y análisis de datos. Consulte las secciones que siguen para obtener información sobre funciones especiales para tipos de archivos específicos.
Los archivos con ciertos formatos, Stata, SPSS, R, Excel (xlsx) y CSV, pueden ingerirse como datos tabulares. Consulte la sección Ingesta de archivos de datos tabulares de esta Guía de usuario para obtener más detalles. Los archivos de datos tabulares pueden ser explorados y manipulados mediante TwoRavens, una aplicación de exploración de datos estadísticos integrada a Dataverse, así como con otras herramientas externas, siempre que se encuentren habilitadas en la instalación de Dataverse que está utilizando. TwoRavens permite al usuario ejecutar modelos estadísticos, ver estadísticas resumidas, descargar subsets de vectores variables y mucho más. Para comenzar, haga clic en el botón “Explorar”, que se encuentra junto a cada archivo de datos tabulares (la aplicación se abrirá en una nueva ventana). Cree y descargue su subset usando TwoRavens. Consulte la sección TwoRavens: exploración de datos tabulares para obtener más información.
Las opciones de descarga adicionales disponibles para datos tabulares, que se encuentran en el menú desplegable debajo del botón “Descargar”, son:
- Como datos delimitados por tabuladores (con los nombres de las variables en la primera fila);
- Formato de archivo original subido por el usuario;
- Guardado como formato RData (si el archivo original no estaba en formato R);
- Metadatos variables (como un archivo XML de DDI Codebook);
- Citas de archivos de datos (actualmente en formato RIS, EndNote XML o BibTeX);
- Todo lo anterior en un paquete zip.
Nuestra integración con WorldMap, una herramienta de análisis y visualización de datos geoespaciales desarrollada por el Centro de Análisis Geográfico de la Universidad de Harvard, permite explorar y manipular shapefiles geoespaciales de forma más amplia. Un shapefile es un conjunto de archivos por lo general cargados/transferidos en formato .zip. Este conjunto puede contener hasta 15 archivos. Se necesitan un mínimo de 3 archivos específicos (.shp, .shx, .dbf) para tener un shapefile válido, y se requiere un cuarto archivo (.prj) para WorldMap o cualquier tipo de visualización significativa.
Los 4 archivos mínimos requeridos para la ingesta de datos en Dataverse y conexión a WorldMap son:
- .shp – formato de forma; almacena la geometría de la entidad en sí;
- .shx – formato de índice de forma; almacena el índice posicional de la geometría de la entidad para permitir una búsqueda rápida hacia adelante y hacia atrás;
- .dbf – formato de atributo; almacena los atributos de columna para cada forma, en formato dBase IV;
- .prj – formato de proyección; almacena los sistema de coordenadas y la información de la proyección, es un archivo de texto sin formato que describe la proyección utilizando un formato de texto conocido.
En un shapefile comprimido, se necesitan al menos 4 archivos con estas extensiones. Se pueden incluir otros archivos dentro del shapefile comprimido, pero no son obligatorios:
- .shp
- .shx
- .prj
- .dbf
Por ejemplo, si los siguientes archivos estuvieran incluidos en un .zip, aparecería el botón “Datos del mapa”:
- subway_line.shp
- subway_line.shx
- subway_line.prj
- subway_line.dbf
Una vez que publique el dataset con el shapefile, podrá utilizar el botón “Datos del mapa” mediante GeoConnect para visualizar y manipular estos archivos de manera que los usuarios puedan explorar los datos geoespaciales en la interfaz de WorldMap. Tenga en cuenta que, para poder mapear su archivo de datos, Dataverse envía una copia de este a la plataforma WorldMap de Harvard. Podrá eliminar mapas y datos asociados a la plataforma WorldMap en cualquier momento.
Los metadatos que se encuentran en la sección de encabezado de los archivos en formato FITS (Flexible Image Transport System) son extraídos automáticamente por Dataverse, agregados y visualizados en los metadatos específicos de astronomía del dataset al que pertenece el archivo. Estos metadatos de archivos FITS, por lo tanto, se pueden buscar y explorar a nivel del dataset mediante los filtros.
Los archivos comprimidos en formato .zip se descomprimen automáticamente. Si por algún motivo un archivo .zip no se pudiera descomprimir, se cargará tal como está. Si el número de archivos que contiene supera el límite establecido (de forma predeterminada, 1000; configurable por el administrador), recibirá un mensaje de error y el archivo .zip se cargará tal como está.
Si el archivo .zip cargado contiene una estructura de carpetas, Dataverse tendrá en cuenta esta estructura. La ubicación de un archivo dentro de la estructura de carpetas se muestra en los metadatos del archivo como “File Path” (ruta del archivo). Cuando descargue el contenido del dataset, se conservará la estructura de carpetas y los archivos aparecerán en sus ubicaciones originales.
Los nombres de carpeta están sujetos a estrictas reglas de validación. Solo se permiten los siguientes caracteres: los alfanuméricos, “_”, “-“, “.” y “ “ (espacio en blanco). Al cargar un archivo .zip, los nombres de las carpetas se limpian automáticamente, y los caracteres no válidos se reemplazan por ‘.’ Las secuencias de puntos se reemplazan por un solo punto. Por ejemplo, el nombre de la carpeta data&info /code=@137 se convertirá en data.info/code.137. Si realiza la carga a través de la interfaz web, el usuario puede cambiar los valores en el formulario de edición, antes de hacer clic en el botón “Guardar”.
Nota: si carga varios archivos .zip en un dataset, los subdirectorios que sean idénticos en varios .zips se fusionarán cuando el usuario descargue el dataset completo.
Existen varias opciones avanzadas disponibles para ciertos tipos de archivos:
- Archivos de imagen: los archivos .jpg, .png y .tif se pueden seleccionar como imagen en miniatura predeterminada para un dataset. La miniatura seleccionada aparecerá en la página de resultados de búsqueda junto a ese dataset.
- Archivos SPSS: los archivos SPSS se pueden etiquetar con el idioma en que fueron codificados originalmente. Para esto, haga clic en “Opciones avanzadas” y seleccione el idioma de la lista proporcionada.
Editar archivos
Diríjase al dataset que le gustaría editar, donde verá la lista de archivos. Seleccione los archivos que quiere editar utilizando la casilla de verificación “Seleccionar todo” o seleccionando los archivos individualmente. A continuación, haga clic en el botón “Editar archivos” que se encuentra sobre la tabla de archivos y, en el menú desplegable, seleccione si desea:
- Eliminar los archivos seleccionados;
- Editar los metadatos (nombre, descripción, etc.) de los archivos seleccionados;
- Restringir los archivos seleccionados;
- Eliminar la restricción sobre los archivos seleccionados (solo disponible si los archivos están restringidos); o
- Añadir etiquetas a los archivos seleccionados.
No tendrá que salir de la página del dataset para completar estas acciones, excepto para editar los metadatos del archivo, lo que lo llevará a la página Editar archivos. Una vez allí, haga clic en el botón “Guardar cambios” para aplicar sus ediciones y volver a la página del dataset.
Si decide restringir los archivos, aparecerá una ventana emergente que le solicitará completar las Condiciones de acceso a los archivos. Si las Condiciones de acceso ya existen, se le pedirá que las confirme. Tenga en cuenta que algunas instalaciones de Dataverse no permiten la restricción de archivos.
Los metadatos de variables se pueden editar directamente a través de una llamada de API, Guía de API: edición de metadatos de nivel variable, o mediante la herramienta Dataverse Data Curation Tool.
El campo de metadatos File Path (ruta del archivo) es la forma en que Dataverse representa la ubicación de un archivo en una estructura de carpetas. Cuando un usuario sube un archivo .zip que contiene una estructura de carpetas, Dataverse completa automáticamente la información File Path para cada archivo contenido en el .zip. Si un usuario descarga el dataset completo o una selección de archivos del dataset, recibirá una estructura de carpetas donde cada archivo está ubicado de acuerdo con su ruta correspondiente.
La ruta de un archivo se puede añadir o editar manualmente desde la página Editar archivos. Al modificar la ruta de un archivo, cambiará su ubicación en la estructura de carpetas que se genere cuando el usuario descargue el dataset completo o una selección de archivos del dataset.
Cuando haya más de un archivo dentro del dataset y al menos uno de estos archivos cuente con una ruta a un directorio no vacío, la página del dataset mostrará una opción para cambiar entre la vista de tabla tradicional y la vista de árbol, que muestran la estructura de carpetas, como en el siguiente ejemplo:
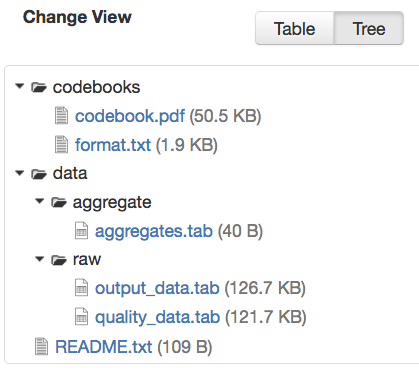
Las etiquetas de archivos se componen de etiquetas personalizadas, de categoría (es decir, documentación, datos, código) y de datos tabulares (es decir, eventos, genómica, geoespacial, red, panel, encuesta, serie temporal). Utilice los menús desplegables, así como la entrada Etiqueta de archivo personalizada para aplicar estas etiquetas a los archivos seleccionados. También, existe una función de eliminación de etiquetas que permite eliminar las etiquetas de archivo no utilizadas dentro de ese dataset.
Reemplazar archivos
Si desea cambiar un archivo existente en lugar de añadir uno nuevo, puede hacerlo mediante la opción “Reemplazar archivo”. Esto le permitirá realizar un seguimiento del historial del archivo en todas las versiones de su dataset, tanto antes como después de reemplazarlo. Esta función puede resultar útil para actualizar sus datos o corregir errores. Debido a que al reemplazar un archivo se crea un vínculo explícito entre la versión anterior del dataset y la versión actual, la función de reemplazo no está disponible para versiones preliminares de datasets sin publicar. Tenga en cuenta además, que al reemplazar un archivo no se transfieren automáticamente los metadatos. Sin embargo, una vez que el archivo es reemplazado, los metadatos originales aún pueden encontrarse en la versión anterior del este, en la pestaña Versiones de la página del archivo.
Para reemplazar un archivo, vaya a la página del archivo, haga clic en el botón “Editar”. En la lista desplegable, seleccione “Reemplazar”. Esto lo llevará a la página “Reemplazar archivo”, donde podrá ver los metadatos de su versión publicada más reciente y cargar el archivo de reemplazo. Una vez que haya completado la carga, puede editar el nombre, descripción y etiquetas del archivo. Cuando haya terminado, haga clic en el botón “Guardar cambios”.
Al reemplazar con éxito un archivo, se genera una nueva versión preliminar del dataset. Un resumen de sus acciones quedará registrado en la pestaña Versiones, tanto en la página del dataset como en la página del archivo. La pestaña Versiones le permite acceder a todas las versiones anteriores del archivo en todas las versiones anteriores de su dataset, incluida la que acaba de reemplazar.
Condiciones
Las condiciones del dataset se pueden ver y editar desde la pestaña Condiciones en la página del dataset o desde el botón desplegable “Editar”. Desde allí puede configurar cómo pueden usar sus datos los usuarios, Licencia CC0 o condiciones de uso personalizadas, y cómo acceder a sus datos si tiene archivos restringidos, “Condiciones de acceso”. También, podrá habilitar un Libro de invitados para su dataset, y así rastrear quién está utilizando sus datos y con qué fin. A continuación, más detalles.
CC0 Dedicación de dominio público
De forma predeterminada, todos los datasets nuevos creados a través de la interfaz web de Dataverse reciben una Dedicación de dominio público de Creative Commons CC0.
La organización Creative Commons define una serie de licencias que permiten a los titulares de derechos de autor divulgar su propiedad intelectual de forma más abierta y con menos restricciones legales que las que imponen los derechos de autor convencionales. Generalmente, cada licencia de Creative Commons específica términos simples sobre cómo se debe utilizar, reutilizar, compartir y atribuir la propiedad intelectual. Además de estas licencias, Creative Commons también proporciona herramientas de dominio público que facilitan la dedicación de la propiedad intelectual al dominio público. En Dataverse, la Dedicación de dominio público CC0 le permite renunciar completamente a cualquier tipo de control sobre la propiedad intelectual de sus datos en todas las jurisdicciones del mundo. Los datos publicados con CC0 se pueden copiar, modificar y distribuir libremente, incluso con fines comerciales, sin violar los derechos de autor. En la mayor parte del mundo, los datos fácticos son libres de derechos de autor, pero la aplicación de CC0 elimina cualquier ambigüedad y clarifica el estado legal de la propiedad intelectual sobre los datos. Dataverse aplica CC0 a los datasets de forma predeterminada para facilitar la reutilización, extensibilidad y preservación a largo plazo de los datos de investigación al garantizar que puedan ser manipulados por cualquier persona sin temor a posibles reclamos de propiedad intelectual.
Si bien mediante CC0 el propietario del dataset renuncia al control legal de la propiedad intelectual sobre los datos, esta licencia no exime a los usuarios de respetar las normas éticas y profesionales para comunicaciones académicas. Las Normas de la Comunidad Dataverse*, así como las buenas prácticas científicas, establecen que se debe dar debido reconocimiento mediante citación. Independientemente de que CC0 se aplique o no, se espera que los usuarios de Dataverse citen los datos que utilizan, reconociendo así a sus autores. Esto se aplica tanto a la Comunidad Dataverse como a toda la comunidad académica en general.
Además, se espera que los usuarios respeten las restricciones de acceso y otras condiciones aplicadas a los archivos con licencia CC0. Otras restricciones, condiciones y términos adicionales pueden ser compatibles con CC0, ya que esta licencia solo se aplica en el ámbito de derechos de autor, que es bastante limitado cuando se trata de datos.
Si el propietario considera que la licencia CC0 no es adecuada para sus datos, puede añadir Condiciones de uso personalizadas, como se detalla en la siguiente sección.
*Aviso legal: las Normas de la comunidad no sustituyen la licencia CC0 ni las condiciones y licencias personalizados aplicables a cada dataset. Las Normas de la comunidad no constituyen un acuerdo contractual vinculante, y la descarga de datasets en Dataverse no crea ninguna obligación legal de observar estas políticas.
Condiciones de uso personalizadas para datasets
Si no utiliza la Dedicación de dominio público CC0 para sus datasets, puede especificar sus propias Condiciones de uso personalizadas. Para hacerlo, seleccione “No, no usar CC0 Dedicación de dominio público”. Aparecerá un cuadro de texto con la leyenda “Condiciones de uso” que le permitirá ingresar sus propias condiciones de uso personalizadas para su dataset. Para añadir información sobre las Condiciones de uso, proporcionamos campos como “Permisos especiales”, “Restricciones”, “Requisitos de citas”, etc.
Encontrará aquí un ejemplo de Acuerdo de uso de datos para datasets (disponible en inglés). Los datos personales han sido anonimizados.
Archivos restringidos + Condiciones de acceso
Si opta por restringir un archivo de su dataset, una ventana emergente le pedirá que ingrese las Condiciones de acceso para los datos. Estas también se puede editar desde la pestaña Condiciones o seleccionando “Condiciones” del botón desplegable “Editar” en la página del dataset. También puede habilitar que los usuarios soliciten acceso a sus archivos restringidos con la opción “Pedir acceso”. Para añadir más información sobre Condiciones de acceso, se proporcionan los campos “Lugar de acceso a los datos”, “Estado de disponibilidad”, “Contactar para solicitar acceso”, etc.
Nota: algunas instalaciones de Dataverse no permiten la restricción de archivos.
Aquí es donde podrá habilitar un libro de invitados o libro de visitas para cada uno de sus datasets, que podrá configurar a nivel del dataverse. Para obtener instrucciones específicas, visite el apartado Libros de visita de datasets en la sección Manejo de Dataverse de esta Guía.
Roles y permisos
Pueden otorgarse roles a las cuentas de usuario de Dataverse. Estos definen qué acciones tienen permitido realizar los usuarios sobre dataverses, datasets y/o archivos específicos. Cada rol viene acompañado de un conjunto de permisos que definen las acciones específicas que pueden realizar los usuarios.
También se pueden otorgar roles y permisos a grupos. Los grupos se definen como una colección de cuentas de usuario de Dataverse, una colección de direcciones IP, por ejemplo, todos los usuarios de las computadoras de una biblioteca, o una colección de todos los usuarios que usan el mismo inicio de sesión institucional, por ejemplo, todos los que inician sesión con cuentas de la misma universidad.
Los administradores o conservadores de un dataset pueden asignar roles y permisos a los usuarios sobre ese dataset. Si es administrador o conservador de un dataset, podrá acceder a la página de permisos del dataset haciendo clic en el botón “Editar”, seleccionando “Permisos” de la lista desplegable y haciendo clic en “Dataset”.
En la página de permisos del dataset, verá dos secciones:
- Usuarios/grupos: aquí puede asignar roles a usuarios o grupos específicos, determinando qué acciones podrán realizar sobre su dataset. También puede visualizar la lista de todos los usuarios que tienen roles asignados para su dataset y eliminar sus roles si así lo desea. Algunos de los usuarios del listado pueden tener roles asignados a nivel de dataverse, en cuyo caso, estos roles solo se podrán eliminar desde la página de permisos del dataverse.
- Roles: aquí puede visualizar la lista completa de roles asignables a los usuarios de su dataset. Cada rol detalla los permisos que ofrece.
Si algún archivo de su dataset tiene acceso restringido, puede otorgar acceso a usuarios o grupos específicos y mantener la restricción al público general. Si es administrador o conservador de un dataset, puede acceder a la página de permisos del dataset haciendo clic en el botón “Editar”, seleccionando “Permisos” de la lista desplegable y haciendo clic en “Archivo”.
Una vez que acceda a la página de permisos de archivo, verá dos secciones:
- Usuarios/grupos: aquí podrá ver qué usuarios o grupos tienen acceso a qué archivos. Al hacer clic en el botón “Dar acceso a usuarios/grupos”, se desplegará un cuadro que le permitirá otorgar acceso a usuarios o grupos específicos para cada archivo de su dataset. Si algún usuario ha solicitado acceso a un archivo, puede aceptar o rechazar la solicitud desde aquí.
- Archivos con acceso restringido: en esta sección, podrá ver la misma información, pero desglosada por archivo. Para cada archivo, puede hacer clic en el botón “Asignar acceso” y se desplegará un cuadro que le permitirá otorgar acceso a usuarios o grupos específicos.
Procedencia de los datos
La procedencia de los datos es un registro que especifica de dónde provienen sus datos y cómo llegaron a tener su forma actual. Describe el origen de un archivo de datos, cualquier transformación que haya sufrido y las personas u organizaciones asociadas con ese archivo. La procedencia de un archivo de datos puede ayudar a la reproducibilidad y al cumplimiento de normas legales. Dataverse permite realizar un seguimiento de la procedencia de sus datos. Actualmente, la información de procedencia solo está disponible para aquellos usuarios con permisos de edición sobre el dataset, pero en un futuro cercano planeamos expandir esta función de manera que la información esté disponible al público. Puede seguir nuestro progreso sobre este tema en el repositorio GitHub de Dataverse.
Dataverse admite información de procedencia en dos formatos: un archivo de procedencia o una descripción de procedencia en texto libre. Puede adjuntar esta información a sus archivos de datos como parte del proceso de carga de archivos, haciendo clic en “Editar” y luego en “Procedencia”:
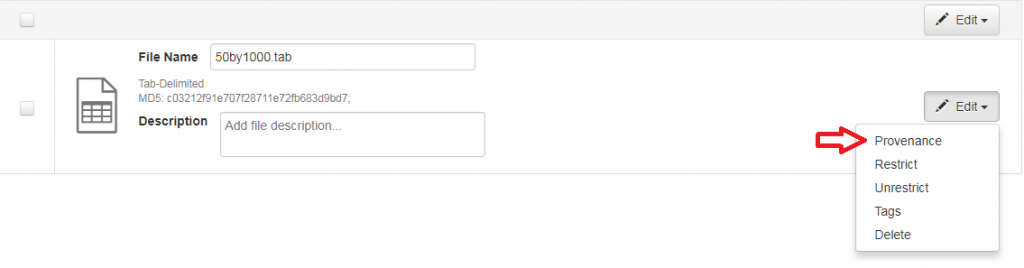
Se abrirá una ventana donde podrá añadir un Archivo de Procedencia y/o una Descripción de Procedencia:
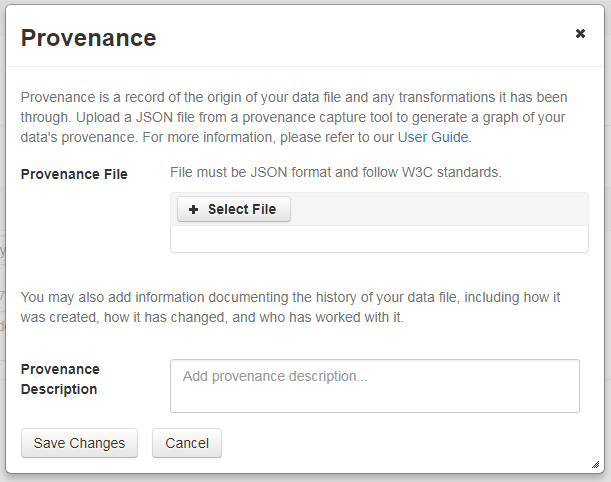
El archivo de procedencia es la forma preferida de enviar información de procedencia a Dataverse porque proporciona un registro detallado y confiable. Normalmente, los archivos de procedencia se generan durante el proceso de análisis de datos, utilizando herramientas de captura de procedencia como provR, RDataTracker, NoWorkFlow, recordr o CamFlow.
Una vez que cargue el archivo de procedencia, Dataverse necesitará información adicional para vincularlo a su archivo de datos de forma precisa. Cuando finalice la carga del archivo, aparecerá un cuadro de entrada con la etiqueta “Conectar entidad” debajo de este. Los archivos de procedencia contienen una lista de las “entidades”, que incluye su archivo de datos, así como cualquier objeto relacionado con él, por ejemplo, un gráfico, un corrector ortográfico, etc. Deberá indicarle a Dataverse qué entidad dentro del archivo de procedencia representa su archivo de datos. Puede escribir el nombre de la entidad en el cuadro o hacer clic en la flecha junto al cuadro y seleccionar la entidad de una lista de todas las disponibles en el archivo de procedencia.
Para obtener más información sobre las entidades y el contenido de los archivos de procedencia, consulte W3C PROV Model Primer.
Una vez cargado su archivo de procedencia y vinculada la entidad adecuada, puede presionar el botón “Previsualización” para ver el JSON sin procesar del archivo de procedencia. Esta función sirve para confirmar que ha cargado el archivo correcto. Asegúrese de verificarlo, ya que el archivo de procedencia se volverá permanente una vez que haya finalizado. A partir de ese momento, ya no podrá reemplazarlo, eliminarlo ni editarlo. Así nos aseguramos que el archivo de procedencia mantenga un registro estable e inalterable del historial del archivo de datos. La permanencia definitiva del archivo de procedencia ocurre en diferentes puntos dependiendo del estado de su archivo de datos. Si se trata de un archivo de datos nuevo que no ha sido publicado, el archivo de procedencia asociado se volverá permanente una vez que se publique el dataset. Si este archivo de datos se ha publicado en una versión anterior de su dataset, el archivo de procedencia asociado se volverá permanente tan pronto como lo cargue y haga clic en “Guardar cambios” en la ventana emergente.
La descripción de procedencia le permite agregar más información además o en lugar de un archivo de procedencia. Es un campo de texto libre donde puede ingresar cualquier información que crea relevante para aquellos interesados en conocer la procedencia de sus datos. Es un buen lugar para indicar factores de procedencia como: qué sistema operativo usó al trabajar en el archivo de datos, qué funciones o bibliotecas usó, cómo se fusionaron los datos en el archivo, qué versión del archivo utilizó, etc. La descripción no es tan útil o confiable como un archivo de procedencia, pero puede tener valor. A diferencia de este, la descripción nunca se vuelve permanente: puede editarla, eliminarla o reemplazarla en cualquier momento.
Puede adjuntar la procedencia a su archivo de datos más tarde haciendo clic en el botón “Añadir + Editar metadatos” en la página del archivo, y luego haciendo clic en el botón “Editar” -> “Procedencia”.
Imágenes en miniatura + Widgets
Se pueden asignar imágenes en miniatura a un dataset de forma manual o automática. La miniatura de un dataset aparecerá en la página de resultados de búsqueda y en la página del dataset. Si un dataset contiene uno o más archivos de datos que Dataverse reconoce como imagen, entonces una de esas imágenes se selecciona automáticamente como la miniatura del dataset.
Si desea seleccionar manualmente la miniatura de su dataset, pude hacer clic en el botón “Editar” en la página su dataset y seleccionar “Miniaturas + widgets” del menú desplegable.
Esto lo llevará a una página donde verá tres posibles acciones debajo de la pestaña Miniatura.
Seleccionar el archivo: haga clic en el botón “Seleccione la minuatura” para elegir una imagen de su dataset para usar como la miniatura del dataset.
Subir archivo nuevo: cargue un archivo de imagen desde su computadora para usarlo como miniatura del dataset. Si bien la imagen en miniatura se extrae de forma predeterminada de los archivos de su dataset, esto le permitirá cargar un archivo de imagen separado para usar como miniatura. Este archivo solo se utilizará como miniatura del dataset y no se almacenará como un archivo de datos.
Borrar miniatura: si hace clic en el botón “Borrar” debajo de la imagen en miniatura, eliminará la miniatura actual del dataset. El dataset volverá a mostrar un icono predeterminado básico como miniatura.
Cuando haya terminado, asegúrese de hacer clic en “Guardar cambios”.
Nota: si lo prefiere, también es posible establecer en su dataset un archivo de imagen como miniatura seleccionando el archivo, y haciendo clic en “Editar archivos” -> “Metadatos”, mediante el botón “Establecer miniatura”.
La función Widgets le proporciona un código que podrá usar en su sitio web personal para mostrar allí su dataset. Hay dos tipos de widgets para datasets: el widget de dataset y el widget de cita de dataset. Encontrará los widgets en la página de su dataset, haciendo clic en el botón “Editar” y seleccionando “Miniaturas + Widgets” del menú desplegable.
En la pestaña Widgets, puede copiar y pegar los fragmentos de código del widget que le gustaría añadir a su sitio web. Si necesita ajustar la altura del widget en su sitio web, puede hacerlo editando el parámetro heightPx = 500 en el fragmento de código.
El widget de dataset permite que las citas, los metadatos, los archivos y los términos de su dataset se visualicen en su sitio web. Cuando alguien descarga un archivo de datos en el widget, se descargará directamente desde su sitio web. Si un archivo está restringido, el usuario será dirigido a Dataverse para iniciar sesión, en lugar de iniciar sesión a través del widget en su sitio web.
Si desea editar su dataset, deberá regresar al repositorio de Dataverse donde se encuentra almacenado. Puede hacerlo fácilmente haciendo clic en el enlace “Data Stored in (Name) Dataverse” (Datos almacenados en [Nombre] Dataverse) que se encuentra en la parte inferior del widget.
El widget de cita de dataset proporciona una cita de su dataset para su sitio web personal o del proyecto. Los usuarios pueden descargar la cita en varios formatos utilizando el botón “Citar datos”. La URL persistente en la cita dirigirá a los usuarios al dataset dentro de su dataverse.
Añadir widgets a un sitio web de OpenScholar
- Inicie sesión en su sitio web de OpenScholar
- Cree una nueva página o navegue hasta la página que le gustaría usar para mostrar los widgets de Dataverse.
- Haga clic en el ícono de configuración y seleccione “Layout” (diseño)
- En la esquina superior derecha, seleccione “Add new widget” (añadir nuevo widget) y en “Misc.” (varios) verá el dataset y los widgets de cita del dataset. Haga clic en el widget que desea añadir, complete el formulario y luego arrástrelo hasta donde desea que se visualice en su página web.
Publicar dataset
Cuando publica un dataset (opción disponible para administradores, conservadores o cualquier rol personalizado que tenga asignado este nivel de permiso), lo pone a disposición del público para que otros usuarios puedan explorarlo o buscarlo. Una vez que su dataset esté listo para publicar, vaya a la página del dataset y haga clic en el botón “Publicar” en el extremo derecho. Se desplegará una ventana emergente para confirmar que está listo para publicar, ya que, una vez que un dataset es publicado, ya no se puede volver atrás.
Si edita su dataset, podrá publicar una nueva versión del mismo. El botón “Publicar dataset” volverá a aparecer cada vez que edite los metadatos del dataset o añada un archivo.
Nota: antes de publicar su dataset, la cita de datos indicará que se trata de una versión preliminar. Tan pronto como se publique, la leyenda “VERSIÓN PRELIMINAR” desaparecerá de la cita.
Enviar para revisión
Si tiene asignado el rol de colaborador (puede editar metadatos, subir y editar archivos, editar condiciones, libros de visitas y enviar datasets para su revisión) de un dataverse, puede enviar su dataset a revisión cuando haya terminado de subir sus archivos y de completar todos los campos de metadatos relevantes. Para enviar a revisión, vaya a la página del dataset y haga clic en el botón “Enviar a revisión”, que se encuentra junto al botón “Editar” en el extremo superior derecho. Una vez enviado a revisión, se notificará al administrador o conservador del Dataverse para que revise y decida “Publicar” o “Devolver a colaboradores”. Si el dataset es publicado, el colaborador recibirá una notificación. Si el dataset es devuelto al autor, se notificará al colaborador que hizo el aporte para que realice modificaciones antes de volver a enviarlo a revisión.
URL privada para revisar datasets sin publicar
La creación de una URL privada para su dataset le permite compartirlo, para ver y descargar archivos, antes de publicarlo, de modo que esté disponible para un grupo de personas que no necesariamente tienen una cuenta de usuario en Dataverse. Las personas que reciban la URL privada no tendrán que iniciar sesión en Dataverse para ver el dataset.
- Vaya a su dataset sin publicar
- Seleccione el botón “Editar”
- Seleccione “URL privada” del menú desplegable
- En la ventana emergente, seleccione “Crear URL privada”.
- Copie la URL privada que se ha creado para ese dataset y ya puede compartirla con cualquier persona que desee, dándole acceso para ver o descargar archivos de su dataset sin publicar.
Para deshabilitar una URL privada y revocar el acceso, siga los pasos anteriores hasta el paso 3 y, en la ventana emergente, haga clic en el botón “Deshabilitar URL privada”.
Versiones de dataset
El control de versiones es importante para la gestión de datos de investigación a largo plazo, donde los metadatos y/o archivo se actualizan con el pasar del tiempo. Esta función se utiliza para realizar un seguimiento de los cambios en los metadatos o archivos (por ejemplo, subida de un archivo, modificaciones en los metadatos de un archivo, agregado o edición de metadatos) una vez publicado su dataset.
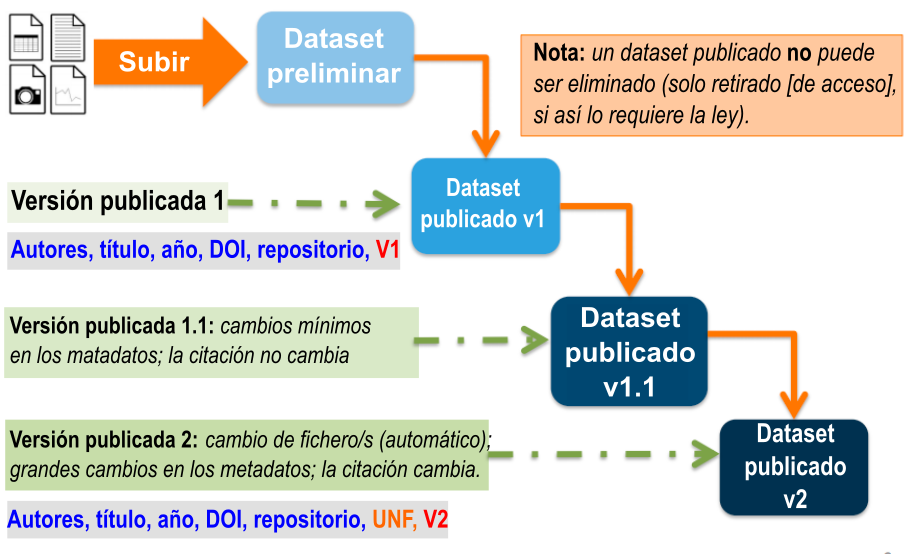
Cuando edita un dataset publicado, se crea una nueva versión preliminar de este. Para publicar la nueva versión, seleccione el botón “Publicar dataset” en el extremo superior derecho de la página. Si se encontraba en la versión 1 de su dataset, según los tipos de cambios que haya realizado, se le pedirá que publique su versión preliminar como versión 1.1 o 2.0.
Nota importante: si añade un archivo, su dataset se actualizará automáticamente a una versión principal, por ejemplo, si la versión era 1.0, ahora será 2.0.
En la pestaña Versiones de la página del dataset, se visualiza una tabla que muestra el historial de versiones del dataset. Puede utilizar los enlaces ubicados en los números de versión de esta tabla para navegar las diferentes versiones del dataset, incluida la versión preliminar sin publicar, siempre que tenga permiso para acceder a ella.
También encontrará la pestaña Versiones en la página del archivo. La tabla de versiones de un archivo muestra la misma información que la tabla del dataset, pero filtrada para mostrar solo las acciones relacionadas con ese archivo. Si se creara una nueva versión del dataset sin cambios en un archivo individual, el resumen de la versión de ese archivo para esa versión del dataset leerá “No hay cambios asociados a esta versión”.
Para ver exactamente qué ha cambiado entre la versión publicada originalmente y las versiones publicadas con posterioridad: haga clic en la pestaña Versiones en la página del dataset. Allí verá todas las versiones y cambios realizados sobre ese dataset en particular.
Si el dataset tiene más de una versión, puede ser simplemente la versión 1 y una versión preliminar, podrá hacer clic en el enlace “Ver detalles” junto a cada resumen para obtener más información sobre los campos de metadatos y archivos que se añadieron o editaron. También puede hacer clic en las casillas de verificación para seleccionar dos versiones del dataset, y luego hacer clic en el botón “Ver diferencias”. Se abrirá la ventana emergente Detalles de las diferencias de versión, donde podrá compararlas.
Métricas de datasets y Make Data Count
Todas las instalaciones de Dataverse cuentan las descargas de archivos. Estos recuentos se agregan e informan a nivel de dataset y a nivel de archivo.
Algunas instalaciones de Dataverse también permiten métricas ampliadas a nivel de dataset (para vistas, descargas de archivos y citas) que utilizan los estándares Make Data Count. Make Data Count es un proyecto de recopilación y estandarización de métricas sobre el uso de datos, especialmente para vistas, descargas y citas. Las citas de los datasets son recuperadas de Crossref a través de DataCite utilizando los estándares de Make Data Count.
Para saber más sobre llamadas de API específicas para Make Data Count, consulte el apartado Dataset Metrics en la sección Native API de la Guía de API.
Almacenamiento y computación en la nube
Las instalaciones de Dataverse pueden configurarse para facilitar el almacenamiento y/o la computación basados en la nube. Actualmente esta característica se considera experimental, y aún estamos resolviendo algunos problemas. Si bien, la configuración predeterminada de Dataverse usa un sistema local de archivos para almacenar sus datos, una instalación de Dataverse habilitada para la nube puede usar una base de datos de almacenamiento de objetos en Swift. Esto permite a los usuarios gestionar los datos utilizando un entorno integrado de computación en la nube.
El botón “Compute” (computar) en las páginas de datasets y de archivos le permitirá computar un solo dataset, varios o un solo archivo. Puede usarlo para crear un lote de cómputo y dirigirse al entorno de computación en la nube integrado a Dataverse.
Acceso al almacenamiento en la nube
Si necesita acceder a un dataset de una manera más flexible que la proporcionada mediante el botón “Compute” (computar), puede usar el cuadro Acceso al almacenamiento en la nube en la página del dataset para copiar el nombre del contenedor del dataset. Este identificador único permite un acceso directo al dataset.
Eliminar acceso a un dataset
Advertencia: no se recomienda eliminar el acceso a un dataset o una versión de un dataset. Esta es una acción muy seria que solo debería ocurrir si existe una razón legal o válida para que el dataset ya no sea accesible al público. En casos absolutamente necesarios, puede eliminar el acceso a una versión de un dataset o un dataset completo.
Para eliminar el acceso, vaya a su dataset publicado, haga clic en el botón “Editar”. En el menú desplegable, seleccione “Eliminar acceso al dataset”. Si existen varias versiones del dataset, puede seleccionar aquí qué versiones desea retirar o puede elegir retirar el dataset completo.
Deberá incluir una razón para la retirada de acceso. Seleccione el motivo más apropiado de la lista de opciones. Si selecciona “Otro”, deberá proporcionar información adicional.
Puede incluir más información adicional sobre el motivo para la retirada de acceso en el cuadro de texto libre. Si el dataset ha sido movido a un repositorio o sitio diferente, le recomendamos que incluya una URL (preferentemente una persistente) de modo que los usuarios puedan acceder a este en el futuro.
Si da elimina el acceso a la versión publicada más reciente del dataset, pero no todas sus versiones, puede volver a visitar una versión anterior y crear una nueva versión preliminar. Por ejemplo, imagine que tiene la versión 1 y la versión 2 de un dataset, ambas publicadas, y decide eliminar el acceso a la versión 2. Luego de realizar esta acción, puede editar la versión 1, lo que generará una nueva versión preliminar.
Nota importante: mediante la URL persistente (Handle o DOI) proporcionada en la cita del dataset, el público podrá acceder a una página de destino con los metadatos básicos del dataset que ha sido retirado. Sin embargo, los usuarios no podrán ver los archivos ni los metadatos adicionales que estaban disponibles antes de que retirara el acceso.